
ZFS Zpool Unavailable
This happened to use after we added some new drives and the drive labels changed. When the ZFS zpool was first created, it probably used drive labels /dev/sdb1, /dev/sdc1, etc. When we added the new drives, the naming was shifted around.
Check your zfs status and list drive labels your zfs pool expects:
$ sudo zpool status
pool: rieseberg1
state: UNAVAIL
see: http://zfsonlinux.org/msg/ZFS-8000-EY
scan: none requested
config:
NAME STATE READ WRITE CKSUM
rieseberg1 UNAVAIL 0 0 0 insufficient replicas
raidz1-0 UNAVAIL 0 0 0 insufficient replicas
sdb1 UNAVAIL 0 0 0
sdc1 UNAVAIL 0 0 0
sdd1 UNAVAIL 0 0 0
sde1 ONLINE 0 0 0
sdf1 ONLINE 0 0 0
sdg1 ONLINE 0 0 0
In the above example, sdb1, sdc1, sdd1 were part of the original ZFS pool. However, those drives were given different labels after we added some extra drives outside of the ZFS, and ZFS was not smart enough to detect the label change.
sudo zpool export rieseberg1 sudo zpool import -f -a
Checking the status shows that the zpool was reimported with the full-id instead of the id.
To fix this, you need to export your zpool and reimport it back again.
$ sudo zpool status
pool: rieseberg1
state: DEGRADED
see: http://zfsonlinux.org/msg/ZFS-8000-EY
scan: none requested
config:
NAME STATE READ WRITE CKSUM
rieseberg1 DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
scsi-1AMCC_9TE06RHJ000000000000-part1 ONLINE 0 0 0
scsi-1AMCC_9TE06HQV000000000000-part1 ONLINE 0 0 0
scsi-1AMCC_5QJ07WEZ000000000000-part1 ONLINE 0 0 0
scsi-1AMCC_5QJ084FM000000000000-part1 ONLINE 0 0 0
scsi-1AMCC_5QJ08MRD000000000000-part1 ONLINE 0 0 0
16609558224110331493 UNAVAIL 0 0 0 was /dev/sdg1
errors: No known data errors
Notice we still have one bad drive. With our raid5 zfs settings, there is enough redundance to rebuild a single drive.
OS Tells Me Drive Is Empty But I Know Data is There
Is the drive mounted? Check df -h. If it is mounted, then it will be listed there.
If it is a zfs drive, you need to mount it differently. zfs mount -a
BIOS Does Not Detect SATA Drive
Ensure that SATA is enabled. If there is an enhanced option, choose it.
Try setting the SATA type to AHCI. Do not use IDE.
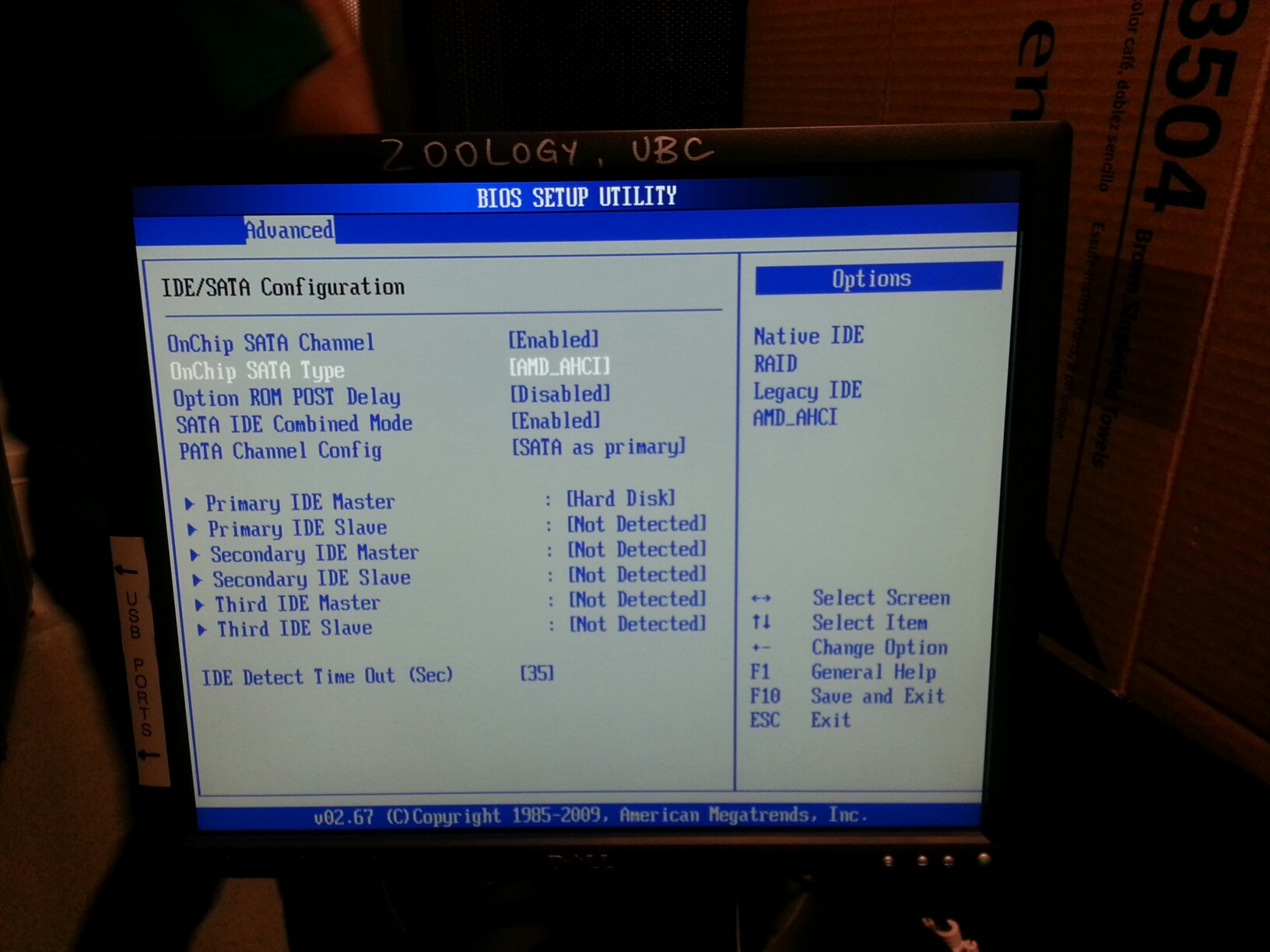
Restart.
Debian 6 Server Installation Stalls While Repartitioning
Order matters when you are partitioning.
Create your root, swap, var, tmp partitions first, then home.
If you want to move the /home directories to another disk, just create the new /home partition on the other disk. The old /home partition will be automatically removed.
If you are partitioning a large drive, it will take a while. For a 2 TB drive, it took about 1 hour to complete. The progress bar won’t budge, so you won’t be able to tell. Just wait.
Breaking up files in an archive for tape backups
Our tapes have an 800GB capacity, so if you want to back something up to tape, you will need to archive it and split it into tape-sized chunks.
I used the zip command to do this:
zip -r -s 800g /PATH/TO/BACKUP-FILE/BACKUP.zip /PATH/TO/FILES-I-WANT-TO-BACK-UP/*
- -s denotes the size of the file (you can specify k, m, or g), and -r tells zip to recursively search folders in the directory you specified and include files and subfolders it finds.
Fail to boot because of fsck errors
fsck checks and fixes badblocks on your disk. By default, it prompts you when it wants to overwrite the badblocks with a fix. If the 6th field of /etc/fstab is non-zero, linux will try to fsck the directory before booting. If fsck fails, you will be prompted for the root password to get into maintenance mode or CTRL-D to continue. The problem is that the OS is in limbo until you tell fsck how to continue.
If you get into maintenance mode, try to run fsck on the drive manually:
fsck -y /dev/sda1
-y chooses yes for all fixes that fsck presents
Replace /dev/sda1 with the partition that has the badblock.
If you are unable to run fsck from the maintenance mode, try booting up with a live CD (not the install CD!). Switch to root user (just type su). Without mounting the bad drive, run the fsck command again and fix any bad blocks. If you get an error saying that the device is busy, then “cd” out of that directory, and ensure that you are specifying the partition that is failing not the entire drive.
Background SmartmonTools Test Fails with “Device XXX not capable of SMART self-check”
This is because SmartmonTools can not detect the drive. Sometimes it is because the drive has a catastrophic failure and can’t spin up. Sometimes the drive is not plugged in tightly.
One time, we got this error on the drive containing the OS and the Smartmon Tools installation. We thought it was weird because if the drive couldn’t be detected, how did Smartmon Tools even run? It turned out that one of the partitions failed fsck upon boot. There was a bad block and fsck was waiting for the user to fix it. The disk and OS were operational enough to run the test, but not operational for anything else useful (like logging on remotely).
How do I find out which drives are available?
Only mounted drives will show up in df -h. To see mounted and unounted drives, you can run gparted or fdisk or list the contents of the /dev/disk directory.
Both gparted and fdisk require root/sudo access. Gparted is a GUI program. Any drives formatted and partitioned with gparted can not be formatted and partitioned with fdisk. However, both programs will list available drives whether they are formatted/partitioned by the other program.
sudo fdisk -l
will list all the drives, the sectors, and sizes, whether or not they are mounted, partitioned, or formatted.
How do I find out which drives are partitioned and formatted?
Go into /dev/disk. There will be several directories: by-label, by-uuid, by-id
List the contents using full listing to see the symlink locations to drives that have been formatted and partitioned.
$ ls -lht /dev/disk/by-uuid/ total 0 lrwxrwxrwx 1 root root 10 Jul 23 19:31 80c07349-db32-4161-a5e7-1303e07b07f1 -> ../../sda1 lrwxrwxrwx 1 root root 10 Jul 23 19:31 d482c9a6-196e-47c2-b403-cefa2a74b567 -> ../../sdc1 lrwxrwxrwx 1 root root 10 Jul 23 19:31 dd06b087-e147-4244-9877-fdc5cc003ea4 -> ../../sdc5 lrwxrwxrwx 1 root root 10 Jul 23 19:31 e7524ec9-fad3-4a2a-9e3a-65158c35a518 -> ../../sdb1
How do I know if my RAID arrays are OK?
If you don’t have a RAID controller management tool installed on the OS, then you will need to enter the RAID controller BIOS. This means you need to restart the machine and wait till the RAID controller BIOS prompts you to start it. It’s best to install a RAID controller management tool that sits on top of the OS, since you can do other tasks while you manage the RAID. Use the RAID controller driver commands to get the status of the RAID arrays. If you notice that a RAID array is rebuilding, do not use the corresponding drive until it is done.
See this blog post for details on checking up on your RAID arrays remotely
Should I use rsync or NFS to transfer files?
I thought NFS would be easier to implement to ensure integrity, and it is. However, when it is set to synchronous write to ensure integrity, it is extremely slow. If you only care about transferring files, use rsync instead. See http://serverfault.com/questions/268369/why-rsync-is-faster-than-nfs.
zpool unavailable
After a power outage, the zpool directory was unavailable with an error message:
# zpool status
pool: reiseberg1
state: UNAVAIL
see: http://zfsonlinux.org/msg/ZFS-8000-EY
scan: none requested
config:
NAME STATE READ WRITE CKSUM
reiseberg1 UNAVAIL 0 0 0 insufficient replicas
raidz2-0 UNAVAIL 0 0 0 insufficient replicas
sdb ONLINE 0 0 0
sdc FAULTED 0 0 0 corrupted data
sdd FAULTED 0 0 0 corrupted data
sde FAULTED 0 0 0 corrupted data
sdf FAULTED 0 0 0 corrupted data
sdg FAULTED 0 0 0 corrupted data
sdh UNAVAIL 0 0 0
The error message: http://zfsonlinux.org/msg/ZFS-8000-EY implies that there was something wrong with importing the zpool drives. What was weird was that no one had tried to export or import the drives.
However, if we explicitly exported the zpool then reimported the zpool, we were able to improve the zpool status from unavailable to just degraded:
# sudo zpool export reiseberg1
# zpool status
no pools available
# zpool status -x
no pools available
# zpool status reiseberg1
cannot open ‘reiseberg1’: no such pool
# zpool import reiseberg1
# zpool status
pool: reiseberg1
state: DEGRADED
see: http://zfsonlinux.org/msg/ZFS-8000-EY
scan: none requested
config:
NAME STATE READ WRITE CKSUM
reiseberg1 DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
sdb ONLINE 0 0 0
2608340253390857278 FAULTED 0 0 0 was /dev/sdc1
5055446710097007850 UNAVAIL 0 0 0 was /dev/disk/by-id/scsi-1AMCC_9TE06HQV000000000000-part1
scsi-1AMCC_5QJ07WEZ000000000000 ONLINE 0 0 0
scsi-1AMCC_5QJ084FM000000000000 ONLINE 0 0 0
scsi-1AMCC_5QJ08MRD000000000000 ONLINE 0 0 0
scsi-1AMCC_5QJ08GAR000000000000 ONLINE 0 0 0
errors: No known data errors
Since there was nothing on the disks anyway, we decided to destroy and recreate the zpools using this command:
$ sudo zpool destroy rieseberg1 $ sudo zpool create rieseberg1 raidz1 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 /dev/sdf1 /dev/sdg1
raidz1 indicates that we want a RAID5 type of implementation. /dev/sd* indicate the disks that we want in the zpool.
Since we did not specify “-m <mountpoint> the rieseberg1 zpool gets mounted into / by default.
If you get an error message
umount: /rieseberg1: target is busy. (In some cases useful info about processes that use the device is found by lsof(8) or fuser(1)) cannot unmount '/rieseberg1': umount failed could not destroy 'rieseberg1': could not unmount datasets
while you are destroying zpools, then it is because the device is busy. Try cd-ing out of the directory, then destroying the associated zpool.
ZFS Hangs and Fails to Import Pool
One time, a drive from the ZFS completely died (no spinning). When we attempted to check the zpool status
zpool status -v
it hung for a long time. We couldn’t even force kill it with (kill -9). Googling around showed that zpool hangs a lot due to various reasons, such as being unable to resolve labels. We’re not sure what exactly cause the hang that time around. But most likely we experienced multiple disk issues and our ZFS was only configured with one disk redundancy. The fact that one of the drives couldn’t even be seen by the ZFS could possibly have messed up the drive labelling system, causing zpool status to hang. Or perhaps the zpool was rebuilding and taking a long time to respond – we didn’t wait long enough to find out.
What was weird was that we were able to export the zpool with no error messages. But when we tried to import the zpool, it was gone. Only an old zpool exported from a long time ago remained. The zpool.cache file, which normally contains info about existing zpools, was completely non-existent.
There is an undocumented -X hack which does a deep traversal of transactions which you could then import. However, it takes a long time and according to various googled blogs only has a 50/50 success rate.. It took 16 hours to import a 3 TB zpool. Good thing for us it worked. Below is the command that worked for us. The same command without -X would fail for us.
zpool import -fFXN rieseberg1
Once done, it output this:
Pool rieseberg1 returned to its state as of Fri 05 Apr 2013 10:03:05 PM PDT. Discarded approximately 58547 minutes of transactions.
We had to attempt the zpool import several times since automatic SMART tests kept running in the middle of the night. Apparently zpool imports are very disk intensive and combined with the SMART tests will crap out an already shaky drive. Always turn off automatic SMART tests when doing zpool imports. Once we did that, our zpool import completed successfully with the -X hack.
Lesson learned: Do not ignore drive SMART failures. Always have some sort of zfs monitoring script/system that tells you when zfs is rebuilding so that you can replace drives. Always back up.